iPhone 13 Pro ワイモバイルとpovo2.0のデュアルSIM環境で 同じ現象で困った人はとりあえず 使用期間2年のiPhone 13 Proでギガが足りなくなってきたので、 快適にしばらくpovo2.0に切替えてギガ回避をしていて、ふと 調べると、iPhoneの仕様で しかもプロファイルをインストールした時の回線にAPNが紐づくらしい。 ところが、全く同じ構成で使っている友人はモバイルデータ通信の切り替えで問題が発生していないという。 ワイモバイルとpovoは別途調べるとiOSが新しければeSIMがいらないとのこと また圏外いやだよーと思いつつ、プロファイルを消してみる。
使用環境
iOS 17
Y!mobile(物理SIM) + povo2.0(eSIM)長いよ3行でまとめて
iPhoneがAPN構成プロファイルを1つしか入れられない仕様により、回線切り替えたら圏外になったが
そもそもiOS 15以上ならAPN構成プロファイルいらないじゃんって話でした。どうしたらいい?
iOS 15以上でAPN構成プロファイル消せば復活するよ。povo2.0契約しました(事の始まり)
ちょこっと調べるとDual SIM対応してるんだ!と今更気づいたので、
povo2.0を契約
入力がフリック入力だとだるいのでPCで契約してたから途中でスマホで設定して、…と少し面倒でした。
さくっとインストールを終えて、手順に従いpovoのAPN 構成プロファイルを入れて...
と、ここが悪夢の始まりだった。切り替えると圏外になった
主回線のワイモバイルのSMSが届かないことに気づいた。
あれー?と思い、povoから主回線Y!mobileに切り替えるも、SMSが届かない。
それどころかモバイルデータ通信でインターネットに繋がらない。
うーん。povo消してみるか、ってことでAPN構成プロファイルを削除
povoのeSIMも消してワイモバイルのプロファイルをWi-Fiで繋いでDLしてインストール
繋がらない\(^o^)/
再起動するか
繋がった。SMSも届いた。
と、2時間程度消耗しました。原因
プロファイルが2つ同時にインストールできないとのこと。
この辺に情報があった。
iPhoneでデュアルSIMする時の問題点〜構成プロファイル | mineo情報館
iPhoneデュアルSIMで格安SIMを使う際の注意点。APN構成プロファイルをインストールで繋がらなくなる問題。 | ビジネス幼稚園
【デュアルSIM(複数SIM)】iPhone の注意点!APN構成プロファイル は2つ使えない!? | ふうカフェ mobile
インストールしなおして何とかなった。
はー、なんなんだよ、これじゃあデュアルの意味ねージャン。
どうすんのー?3大キャリアのだと最初からAPNの情報をSIMが持っていてそれならいけるって話もあるが。
と思っていました。
さらに調査すると新しい事実が判明した。そもそもAPN設定はiOS 15以上ならいらない
構成プロファイルを見せてもらうと何も入っていない…だと?
気になって調べてみた。
このiPhoneは2年ほど使っていて、MVNOのとかはAPNをいれるのを前提としていたが、
(というより、データコピーしてiPhone引き継いでるのもあってiOS 14以前に入れたものだろう)
そもそも、キャリアが対応していればだが、iOS 15あたりからAPNなしで通信できるらしい。
この辺ちゃんと追ってないと全然わからないですね。
ワイモバイル
ワイモバイル回線の通信設定をする|SIMフリー iPhone/iPad|ワイモバイルスマホの初期設定方法|Y!mobile - 格安SIM・スマホはワイモバイルで
明示的に書いてないがAPN構成プロファイルは新しめの機種なら入れるようには書いてない。
povo2.0
https://kdlsupport.zendesk.com/hc/ja/articles/4405874198543-APN%E8%A8%AD%E5%AE%9A%E3%81%AF%E5%BF%85%E8%A6%81%E3%81%A7%E3%81%99%E3%81%8B
iOS 15以上ならいらないと書いている。実際にやってみる
別にいらないSoftbank一括設定というのもあるが、それは残す。
この状態でワイモバイルで繋いでみる→繋がった。
eSIMを復活させて…と思ったら再発行が必要なのか…時間外じゃん。
「データ専用」プランの場合、eSIMの再発行はできません。
┌(┌՞ਊ՞)┐キェァァァェェェェァァァwww
…いつか検証する。
MyBatis Generatorを使ってコードの自動生成をしてみる

皆さんJavaでORMは何を使っているでしょうか?だいたいJPA(Hibernate)かMyBatisだと思いますが、
Hibernateはやりたいことに対して複雑すぎるのがあって敬遠していると思います。
そこでMyBatisなのですが、何かと書くの面倒、楽したいってのはあると思います。
そこで検討してみるのがMyBatis Generatorではないでしょうか。というので、導入方法の紹介です。
今回やってみたのはアノテーションでの自動生成方法です。
XMLでの生成も簡単に設定で変えられます。
- 前提条件
- MarketplaceからMyBatisGeneratorを入れる
- PostgreSQLをインストール
- 適当なデータを用意する
- Spring Boot Projectを作成する
- 設定ファイルを整備する
- コードの自動生成
前提条件
コマンドラインで使えるMavenが入っていること
Eclipse Pleiades のJava Full Editionを入れとく
Pleiadesは昔重すぎて、余計なのがたくさんついてる印象であまり好きでなかったですが、
久々に使ってみるとよいです。いまだと必要なものだけが入っていていい感じ!
プラグインの相性が悪い変なハマりも少なくていいかも。
英語化したい場合は
[eclipseのインストールフォルダ]\eclipse\eclipse.iniファイルを変更
-javaagent:dropins/MergeDoc/eclipse/plugins/jp.sourceforge.mergedoc.pleiades/pleiades.jarの行を削除
最後の行に-Duser.language=en_USを追加
これでEclipseを再起動する
MarketplaceからMyBatisGeneratorを入れる
MarketplaceからMyBatis Generator 1.4.2をEclispeに入れる。
PostgreSQLをインストール
普通にインストールする。
Macの場合はここ参照
適当なデータを用意する
https://www.postgresqltutorial.com/postgresql-getting-started/postgresql-sample-database/
Spring Boot Projectを作成する
Name: demo-mybatis-generator Type: Maven Packaging: Jar Java Version: 17 Language: Java
Lombok, Spring Boot DevTools, Spring Web がデフォルトで選ばれていると思うけど、
これに加えて
MyBatis Framework, PostgreSQL Driver, Thymeleaf を追加で入れる。
設定ファイルを整備する
src/man/resources/application.properties に以下を追記
spring.datasource.driver-class-name=org.postgresql.Driver spring.datasource.url=jdbc:postgresql://localhost:5432/dvdrental spring.datasource.username=postgres spring.datasource.password=postgres
※用意したデータの場合です。
pom.xmlの編集
https://mybatis.org/generator/running/runningWithMaven.html
を参考に
pom.xmlに次を追記する。
<build> <plugins> <plugin> ...(関係ないので省略) </plugin> <plugin> <groupId>org.mybatis.generator</groupId> <artifactId>mybatis-generator-maven-plugin</artifactId> <version>1.4.2</version> <configuration> <configurationFile>${project.basedir}/src/main/resources/generatorConfig.xml</configurationFile> <overwrite>true</overwrite> </configuration> <executions> <execution> <id>Generate MyBatis Artifacts</id> <goals> <goal>generate</goal> </goals> </execution> </executions> <dependencies> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>${postgresql.version}</version> </dependency> </dependencies> </plugin> </plugins> </build>
※Eclipseから実行する場合はいらないところがいくつかあります。
generatorConfig.xmlの編集
Javaの場合はtargetRuntimeで指定する生成方法で3つの方法があり、大きく次の特徴があります。
| MyBatis3DynamicSql | MyBatis3 | MyBatis3Simple | |
|---|---|---|---|
| コード生成量 | 少なめ | 多い | 少ない |
| 使うクラス | MyBatis Dynamic SQL | ~Example | 普通のMapper |
| Annotation/XML | Annotation | 選択可 | 選択可 |
デフォルトはMyBatis3DynamicSqlでタイプセーフでコード生成量も比較的少なく
そのままで柔軟なクエリが欠けるといった特徴があります。
しかし、独自DSLみたいな書き方を強制されるので人を選ぶ感じがあります。
自分で書く場合はAnnotationベースで書いちゃうって場合が多いと思います。
その場合、MyBatis3Simpleが多くの場合適してるのではないかと思います。
src/main/resources/generatorConfig.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" > <generatorConfiguration> <!-- 生成タイプはMyBatis3Simpleを選びます --> <context id="postgres" targetRuntime="MyBatis3Simple"> <!-- 生成コメントの設定 --> <commentGenerator> <property name="suppressAllComments" value="true" /> </commentGenerator> <!-- DB接続設定 --> <jdbcConnection driverClass="org.postgresql.Driver" connectionURL="jdbc:postgresql://localhost:5432/dvdrental" userId="postgres" password="postgres"> </jdbcConnection> <!-- Entityの設定 --> <javaModelGenerator targetPackage="com.example.demo.entity" targetProject="src/main/java"> </javaModelGenerator> <!-- Mapper(XML)の設定 --> <!-- <sqlMapGenerator targetPackage="com.example.demo.mapper" targetProject="src/main/resources"> </sqlMapGenerator> --> <!-- Mapper(Java)の設定 --> <javaClientGenerator type="ANNOTATEDMAPPER" targetPackage="com.example.demo.mapper" targetProject="src/main/java"> </javaClientGenerator> <!-- コードを生成するテーブルを指定 --> <table tableName="actor" modelType="flat"> </table> </context> </generatorConfiguration>
かなり細かい設定ができますので、気になる方は、こちらを参照。
MyBatis Generator Core – MyBatis Generator XML Configuration File Reference
この設定の場合、自分でMapper書きたいなと思えば、簡単に追加することができます。
自動生成したコードを直接触るのはどうなの?とかいうのはあるかと思いますが、
そこはプロジェクト次第だと思います。
コードの自動生成
コマンドプロンプトから
mvn mybatis-generator:generate
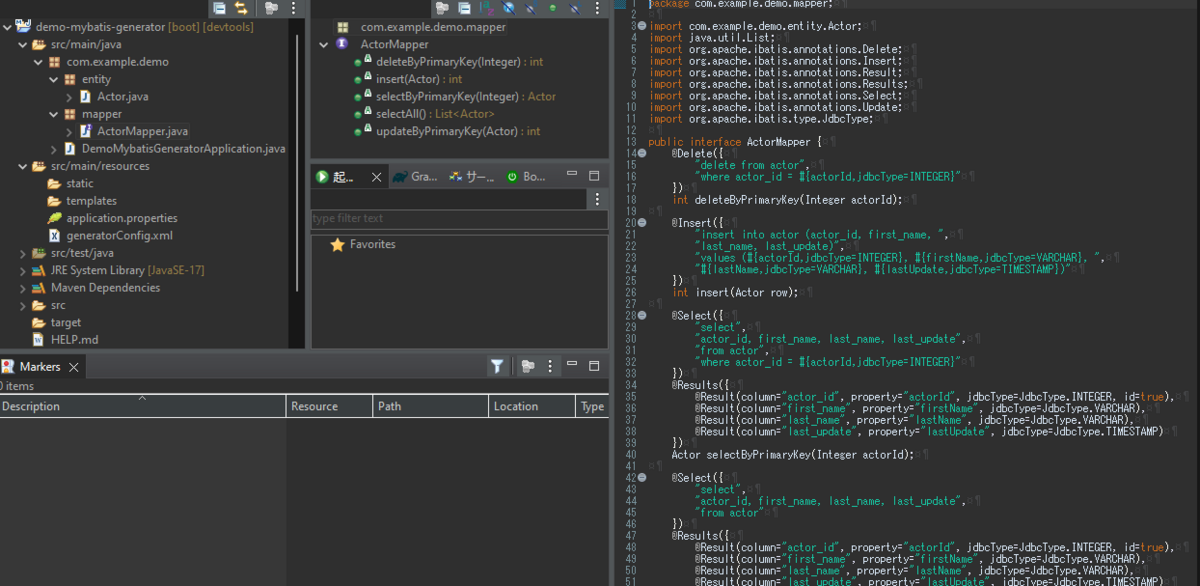
この例ではentity配下にActor.java
mapper配下にActorMapper.java
が生成されます。
Homebrew経由でPostgreSQL14をインストール

インストール直後何をすればいいのかよく忘れるのでメモ
前提条件
M1 Mac
シェルはbash
Homebrewをインストール済み
echo $SHELLで/bin/zshならzshです。
もし変えたい場合は先におまけから
インストール
Homebrew経由でPostgreSQL14をインストール
brew install postgresql@14
@の後ろがバージョン番号です。
あとは基本的にTerminalに表示されるまま
デフォルトがzshの場合はこれではなく表示される手順に従ってください。
ログイン時にパスを通す(bash)
(echo; echo 'eval "$(/opt/homebrew/bin/brew shellenv)"') >> ~/.bash_profile
現在のシェルでPATHを通す
eval "$(/opt/homebrew/bin/brew shellenv)"
サービスを起動する
brew services start postgresql@14
サービスの一覧を確認する
brew services list
データベースの初期化をする
initdb --locale=C -E UTF-8 /opt/homebrew/var/postgresql@14
スーパーユーザ作成
createuser -P -s postgres
繋いでみる
createuser -P -s postgres
繋げたら\qで終了
パスワードを聞かれるようにする
vim /opt/homebrew/var/postgresql\@14/pg_hba.conf
trustをmd5にする
# "local" is for Unix domain socket connections only local all all trust # IPv4 local connections: host all all 127.0.0.1/32 trust # IPv6 local connections: host all all ::1/128 trust
# "local" is for Unix domain socket connections only local all all md5 # IPv4 local connections: host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 md5
brew services restart postgresql@14
おまけ bashをデフォルトにする方法+αの設定
chsh -s /bin/bash
vim ~/.bash_profile
HOST='\u@\h' PS1="\[\033]0;$HOST\007\]" # set window title PS1="$PS1"'\n' # new line PS1="$PS1"'\[\033[32m\]' # change color PS1="$PS1"'\u@\h ' # user@host<space> PS1="$PS1"'\[\033[33m\]' # change color PS1="$PS1"'\w' # current working directory PS1="$PS1"'\[\033[0m\]' # change color PS1="$PS1"'\n' # new line PS1="$PS1"'$ ' # prompt: always $ # "-F":ディレクトリに"/"を表示 / "-G"でディレクトリを色表示 alias ls='ls -FG' alias ll='ls -alFG'
※ ~/.bashrcでもいい。というか、本当はこっちが正しい。
本当に正しい .bashrc と .bash_profile の使ひ分け #Bash - Qiita
WindowsからMacへファイル共有をする
 久々にWindowsのファイルをMac側に送りたいなとおもったらプチハマりしたのでメモ
久々にWindowsのファイルをMac側に送りたいなとおもったらプチハマりしたのでメモ
どうせ次やるときにはまた忘れて同じハマりを繰り返すのだ。
いまどきCDやUSBのデバイスを使って転送するのもアレだし
わざわざこれだけのためにクラウドストレージ使うのもあほらしいし、
ローカルネットワーク内で何とかしたいと思ったときにはまりがちなやつ
Windows Defenderでも起こるかも。
Firewallに阻まれるのはよくあること。
この記事は最低限のネットワークの知識がない人には役立たないかもしれない。
環境
ファイル共有側
OS: Windows11 ウィルス対策ソフト: ESET
ファイル取りたい側
OS: macOS Ventura 13.5 ウィルス対策ソフト: ESET
とりあえず長ったらしいので
WindowsからMacへの共有方法はコチラの通り。Write権限は別に与えんでもいい。
WindowsとMacの間でファイル共有をする方法 | パソコン工房 NEXMAG
Windws Defenderかウィルス対策ソフトのファイヤーウォールをOFFってみれば解決すると思うよ!!
症状
DHCPでWi-FiでPCを複数台使っている(※一部固定IPはある)。
同じセグメントにいるのにMacからWindowsのフォルダが読めない。
うちではCIDR表記で192.168.3.0/24がデフォルトの設定になっている。
古き良きSMB、これは慣れてるからさすがにできるだろ、と思ったらできない。
わざわざWindows側でSMBを有効化してsmb://[IPアドレス]の形式でもアクセスできない。
そればかりかpingも通らない。
なぜか逆方向のWindowsからMacからのpingは通る(おいおいどういうことだよESETさんてばよ)。
といった状態だった。
ファイヤーウォール?ファイアウォール?Firewallが怪しくね?(表記どれが正しいの?)
と思ったらやっぱりこれだった。
解決策
ここの手順をすれば基本的にWindowsのデフォルト設定で共有できます。
Mac側も何か設定があるとすればネットワーク関連の設定で
WINSの設定でワークグループがWORKGROUPになっていればOK
Macで「WINS」設定を変更する - Apple サポート (日本)
デフォルトで設定されてるはず。
どうせ共有なんて普段しないんだからESETのファイヤーウォールを一時的にOFFる
恒久的な対策はいつか書きます(たぶん)。
おまけ
Thunderbirdを移行したくてやった。
特にメッセージフィルタがアレなんで、あれをあれしてはこれ
Thunderbirdのメッセージフィルタを移行する #thunderbird - Qiita